
")
Model Class Reliance (MCR) for Variable Importance
Understanding phenomenon via modeling & post-hoc variable importance is currently flawed.
This is due to shared information in the input features leading to multiple “best” performing models which use the input variables to different degrees (i.e. exposes different, equally valid explanations of the phenomena). Considering a single, arbitrary, model (explanation) is misleading at best.
This project builds on the original work on Model Class Reliance (Fisher et. al. 2019) to address this contributing novel algorithms and methods.
Understanding phenomenon via modelling & post-hoc variable importance is currently flawed.
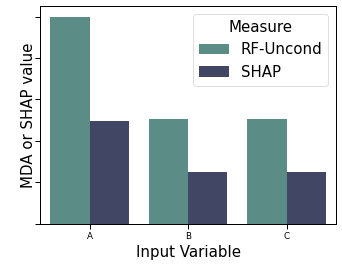
When the measured variables are not independent, multiple models exist. Without knownledge of the causal process (often what is being investigated in the first place) machine learning algorithms will arbitrarily build one. Considering variable importance (or SHAP, or LIME) of such a model is a best arbitrary though more likely misleading / wrong.
This project aims to address these issues, providing novel methods and algorithms to correctly examining phenomenon by acknowledging and explicitly accounting for the fact that measured features share information regarding the output. The approaches in many cases can be used as direct drop in replacements within machine learning pipelines for variable importance and other methods such as SHAP. For instance our work on MCR for Random Forests provides the approaches for Random Forests via Python estimators which are drop in replacements for their sklearn counterparts.
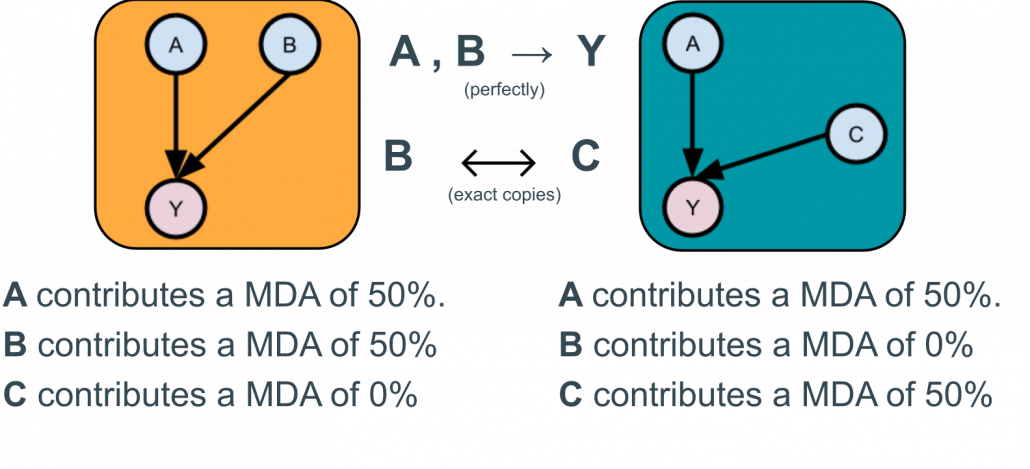
Machine learning models highlight the best predictive relationship between the inputs and outputs.
Variable importance details this relationship. But often there is more than one best predictive relationship. This set of models is known as the Rashomon Set.
When undertaking model building and explanation, all models other than the one built are ignored by current analysis and subsequently when attempts are made towards phenomenon understanding following such an approach. Unfortunately, the one considered is arbitrary and chosen (typically silently) by the machine learning algorithm.
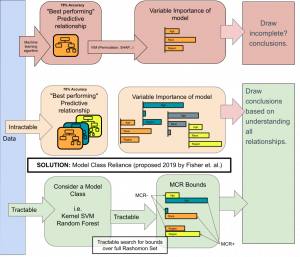
Model Class Reliance (MCR) acknowledges and addresses this issue, providing upper and lower bounds of (input) feature importance by (typically implicitly for computational reasons) considering the whole Rashomon Set. This communicates to the practitioner the most or the least a variable may be used by any predictive model that is able to achieve maximal predictive accuracy. When considering the importance of a variable to the phenomena, this correctly indicates to practitioners the uncertainty in the variables causal nature in predicting the phenomena which is inherent due to the fact that (1) the data is purely observational and contains shared information and (2) no external causal knowledge has been provided.
This research extends state-of-the-art in MCR, providing new algorithms to (tractably) compute MCR for Random Forests (Classifiers and Regression) along with variants and extensions to aid practitioners/researchers in understanding phenomenon through learning (non)linear models. Recently completed work include grouped-MCR, MCR-SHAP with other variants and extensions currently under development.
In 2019 a MCR method for (regularised) Linear and Kernel Regression under squared loss was proposed in the seminal work by Fisher et. al [1].
Stage 1 of this work: First MCR method for Classification & Regression Random Forest (published in [2]). A Python implementation is available.
We provided proofs of correctness in the limit, empirical evidence of fast convergence & a linearithmic runtime implementation (vs. Polynomial from [1]).
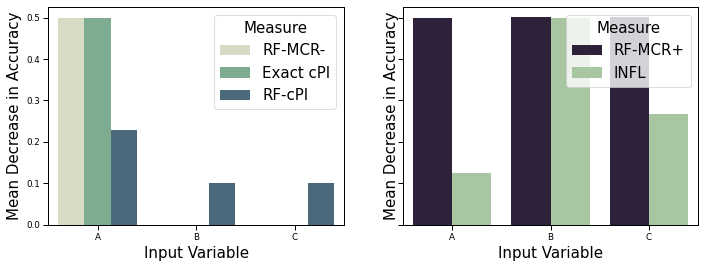
We compared to SVM-MCR [1] (for regression) and a baseline of 2 other approaches best representing MCR- and MCR+ (for classification), showing:
- multiple “best models†do exist. Different predictive mechanisms lead to different possible variable importance scores (wide MCR ranges).
- RF-MCR performs correctly and is able to identify these ranges.
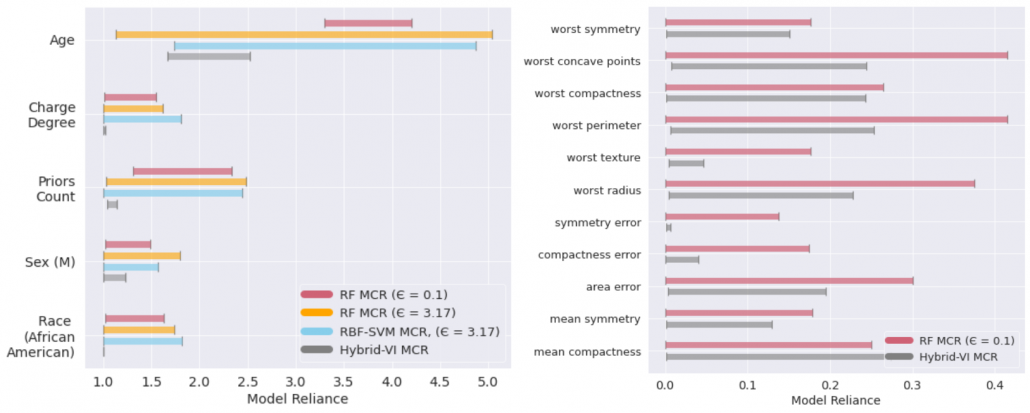
Left: MCR bounds for COMPAS – Recidivism Modelling (a regression task)
Right: Breast Cancer Wisconsin dataset (a classification task, hence the method from [1] is not compared)
Model Class Reliance for Random Forests
Variable Importance (VI) has traditionally been cast as the process of estimating each variable’s contribution to a predictive model’s overall performance. Analysis of a single model instance, however, guarantees no insight into a variables relevance to underlying generative processes. Recent research has… [more]
Group-MCR for RF-MCR is introduced in:
Ljevar, V., Goulding, J., Smith, G. and Spence, A. “Using Model Class Reliance to measure group effect on adherence to asthma medication”. (IEEE International Conference on Big Data (Big Data). IEEE, 2021.).
Pre-print | Proceedings
- Github repository containing a pip installable, sklearn compatible, Python implementation of MCR for Random Forests.
- Extended presentation given at TU Wien, slide deck available here.

